Dans un contexte IT où le volume d’informations explose, disposer d’un outil de métriques puissant devient essentiel. Mais les méthodes traditionnelles de supervision peinent parfois à donner une visibilité suffisamment granulaire et réactive. C’est dans ce contexte que Prometheus s’impose comme une pierre angulaire de l’observabilité moderne.
Dans cet article, nous vous proposons une plongée technique dans Prometheus, ses forces et usages. Nous verrons aussi les avantages à l’associer notre solution d’hypervision Open Source, Canopsis.
Présentation générale de la solution
Prometheus est une solution open source de surveillance (monitoring) centrée sur les métriques en séries temporelles. Initiée en 2012 chez SoundCloud, elle devient par la suite un composant clé de l’écosystème Cloud Native. En 2016, cette initiative rejoint d’ailleurs la Cloud Native Computing Foundation (CNCF).
Ses principes architecturaux marquants sont :
- Base de données de séries temporelles : L’outil stocke des métriques associées à des horodatages, souvent enrichies d’étiquettes (tags).
- Modèle de collecte « pull » : Prometheus interroge périodiquement des points d’exposition HTTP (/metrics) sur les applications ou exporters. Cela lui assure ainsi un contrôle précis de la collecte et des données cohérentes.
- PromQL : Ce langage, très riche, donne la possibilité de formuler des requêtes complexes pour agréger, filtrer, corréler des métriques.
- Alerting intégré : Prometheus intègre un système d’alarme, Alertmanager, capable de :
- Gérer la suppression des alertes redondantes,
- Définir des conditions,
- Expédier les notifications selon des règles,
- Et d’effectuer des regroupements.
Prometheus s’appuie sur une multitude d’exporters pour capturer des métriques de chaque couche :
- infrastructure (serveurs, OS)
- services applicatifs,
- bases de données,
- réseau…
Dans la plupart des cas, il s’intègre également avec Grafana pour visualiser et construire des tableaux de bord interactifs :
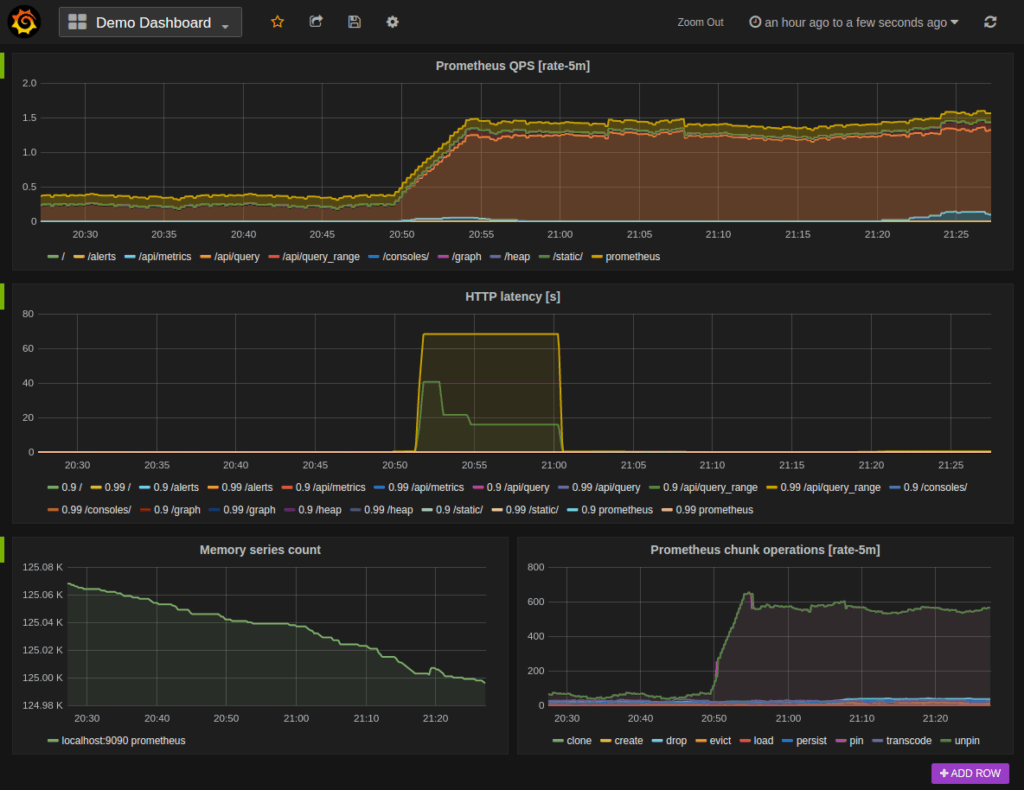
Avantages techniques et fonctionnels de Prometheus
Voici ce que Prometheus apporte concrètement, au-delà des capacités fondamentales.
Avantages techniques
- Flexibilité et multi-dimensionnalité
L’usage des labels permet de trier, agréger et découper les métriques selon divers axes (instance, version, région, type de service). Très utile pour les infrastructures distribuées !
- Scalabilité et modularité
Prometheus est léger par nature. Cependant, il a la possibilité de monter en charge via des architectures fédérées, des clusters, du remote write ou des composants tiers d’ingestion. Analystes, exploitants, ingénieurs peuvent donc répartir les charges selon les zones géographiques ou fonctions.
- Précision dans l’alerte
Grâce à la combinaison du stockage local rapide, des règles d’alerte fines et de la faible latence dans la collecte, Prometheus permet des alertes précoces et fiables.
- Interopérabilité et intégrations
De nombreuses plateformes s’intègrent à Prometheus de façon à ingérer ou exporter des métriques. Par exemple, Elastic propose une intégration Prometheus qui permet de collecter via exporters, Remote-Write ou requêtes PromQL.
Avantages fonctionnels
- Visibilité en quasi-temps réel
Pour les opérations critiques, pouvoir observer la charge CPU, les latences, les erreurs applicatives ou d’infrastructure en quasi temps réel est en effet un avantage stratégique !
- Polyvalence des cas d’usage
- Monitoring d’infrastructures physiques ou virtuelle
- Supervision de conteneurs / Kubernetes
- Suivi des applications métier (temps de réponse, erreurs)
- IoT et dispositifs embarqués (avec certaines limites selon la fréquence et la cardinalité)
- Prévention pro-active des incidents
- Visualisation et exploration des tendances
Avec des dashboards (Grafana ou autres), on peut aussi analyser les tendances, prévoir les pointes de charge, détecter les anomalies, faire de la capacité ou modéliser la performance pour les SLA.
- Réduction des coûts
Open source = pas de frais de licence. Le coût réside dans le dimensionnement (stockage, instances), mais la flexibilité permet un usage optimisé.
Ce que Prometheus peut faire combiné à Canopsis
Maintenant que nous avons vu ce qu’est Prometheus et ses forces, intéressons-nous à ce qu’on peut obtenir en le combinant avec notre solution d’hypervision Open Source comme Canopsis.
Synergie entre événements et métriques
Canopsis agrège des événements issus de superviseurs, référentiels, logs, CMDB… Prometheus fournit quant à lui les métriques en continu : latences, taux d’erreurs et utilisation de ressources.
En combinant les deux, on peut non seulement détecter des alertes via Canopsis, mais disposer du contexte métrique qui les a générées, permettant un diagnostic plus rapide.
Connecteur Prometheus pour Canopsis
Prometheus, couplé à Alertmanager, permet de générer des alarmes qui seront reçues par le connecteur Canopsis dédié. Il se présente sous la forme d’un récepteur de webhook Alertmanager. Les webhooks reçus sont transformés en événements Canopsis.
Cas d’usage concrets
- Diagnostic d’incident accéléré : une alerte déclenchée dans Canopsis peut afficher, dans son panneau, les métriques associées grâce à Prometheus – latence d’entrée, CPU/mémoire sur services pertinents, erreurs intermittentes.
- KPIs / tendances métiers : recueil des métriques métiers exposées via Prometheus et intégration dans Canopsis pour reporting, journaux de bord, ambiances de service, cartographie d’impact.
- Réduction de bruit / fausses alertes : métriques permettant de vérifier si une alarme est due à un pic/goulot temporaire ou si c’est réellement un problème stable, et Canopsis peut filtrer selon ces métriques.
- Automatisation / remédiation : alertes Prometheus → Canopsis → déclenchement d’actions ou workflows automatiques ou semi automatiques, tickets, escalades selon les indicateurs.
- Corrélation : les alertes Prometheus sont agrégées dans la console unique de Canopsis et permettent de confirmer ou d’infirmer les alarmes reçues, en appliquant des règles de corrélation.
Avantages pour les utilisateurs de Canopsis
- Vision complète du SI : métriques + alarmes + logs + référentiels dans une seule et même couche de pilotage.
- Réduction des faux positifs/faux alarmes : en combinant métriques (ex : charge ou taux d’erreur) et évènements, on peut éviter d’alerter pour des incidents temporaires ou non significatifs.
- Meilleure réactivité : l’exploitation dispose d’un bac d’alarme centralisé (Canopsis) enrichi des métriques en temps réel, facilitant les décisions rapides.
- Historique, reporting, KPI puissants : avec Prometheus comme source métrique fiable, Canopsis peut offrir des rapports plus robustes, des comparaisons dans le temps, des analyses de capacité…
Pour conclure sur Prometheus… et Canopsis !
Prometheus est donc un outil de supervision extrêmement performent pour collecter, stocker et interroger des métriques à haute fréquence, via des exporteurs. Avec Alertmanager, ses alarmes peuvent être transmises à un outil d’hypervision comme Canopsis qui réduira le « bruit », évitant ainsi de noyer les utilisateurs dans des alarmes non pertinentes.
De la métrique Prometheus à la météo des services Canopsis : le connecteur Prometheus participe au calcul des indicateurs métiers de la météo des services, en associant les métriques reçues à d’autres sources d’information.
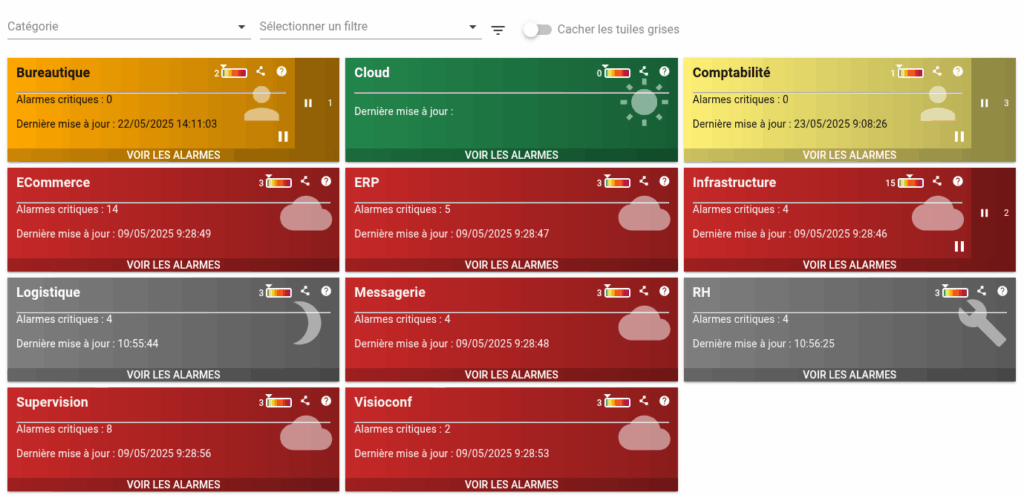
Si vous utilisez Canopsis, l’intégration de Prometheus est une étape naturelle pour :
- gagner en visibilité granulaire,
- diagnostiquer plus vite,
- réduire les temps d’arrêt,
- améliorer la satisfaction des utilisateurs internes/externes.
Envie d’en savoir plus sur ce que Prometheus et Canopsis peuvent faire pour votre SI ? Venez échanger avec nos experts Open Source !